
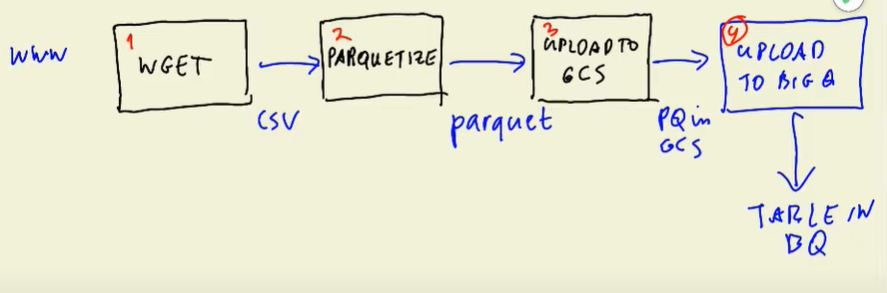
Following last weeks blog, we move to data ingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This was used to test our setup. This week, we got to think about our data ingestion design. We looked at the following:
- How do we ingest – ETL vs ELT
- Where do we store the data – Data lake vs data warehouse
- Which tool to we use to ingest – cronjob vs workflow engine
NOTE: This weeks task requires good internet speed and good compute. If your computer is less than 8gb, you should use the VM created in week 1
ETL vs ELT
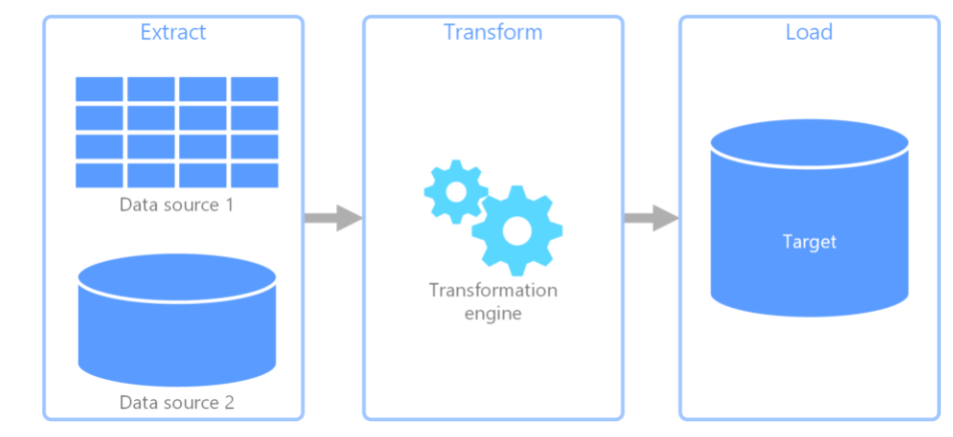
ETL means Extract Transform and load. It is mostly used when you have multiple sources of data. The transformation step takes place in a separate engine and the transformed data is stored in a data store. The process is slow since the data has to be transformed first. An example might be an business with multiple clients having instances of their application. The BI team wants to do analysis of the data. The multiple databases will be queried, then passed through the transformation server to transform the data to comply with the business rule then the transformed the data is stored in a data store. This is also used for legacy systems.
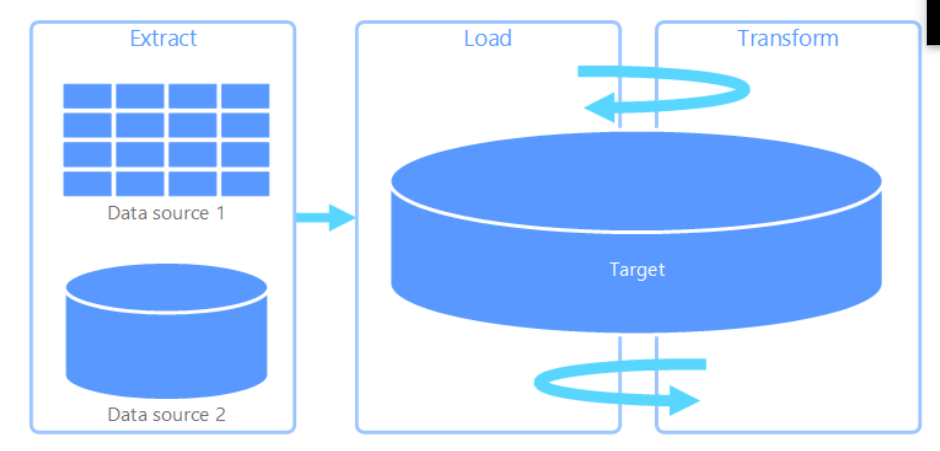
ELT means Extract Load and Transform. What differentiates it from the ETL is that the transformation takes place in the data store. This means that your data store has to have capabilities of transforming the data. It is mostly used for big data. The data ingestion takes less time compared to ETL. It is also preferred when the use case has more diverse business intelligence. When the business intelligence needs change, they can go query the raw data again.
Data Lake vs Data Warehouse
Data lake stores raw data. The purpose of the data is not determined. The data is easily accessible and is easy to update. Disadvantages of a data lake are:
- Can easily become a data swamp
- data has no versioning
- Same data with incompatible schemas is a problem without versioning
- Has no metadata associated
- It is difficult to join the data
Data warehouse stores processed data, mostly structured data. The data is in use and is difficult to update.
Data Workflow Orchestration
This specifies how the data flows, what are the dependencies of each step and what are the jobs. You should not have two steps in one script. It is called Idempotency. Tasks should not be affected depending on how many times it is run. Some of the work engines available are:
For this exercise, we had to separate the downloading of the data with saving the data to the database.
The workflow can be achieved using cronjobs. This is what we used for one of projects at Hepta Analytics called mahewa. For this project however I wish I new of the workflow engines since it took me months to synchronize the cronjobs. For workflow with only one task or tasks with predictable behaviors, a cronjob works.
APACHE AIRFLOW
This is an opensource platform that lets you build and run workflows. Workflow is a compilation of tasks, showing their dependencies and the flow of data. The workflow is know as DAGs (Directed Acyclic Graph). Acyclic here stands for not cyclic, not regularly updated. Airflow installation has the following components:
- Scheduler – triggers the scheduled workflow and submits tasks to be done
- Executor – runs tasks. In production, the execution is done by workers
- Webserver – The user interface
- DAG files – what the scheduler and executor reads
- Metadata database – stores the state of webserver, executor and scheduler
Setting up Apache Airflow
First thing is to move the location of your gcp key
cd ~ && mkdir -p ~/.google/credentials/
mv <path/to/your/service-account-authkeys>.json ~/.google/credentials/google_credentials.jsonThe you have to upgrade docker-compose version to 2.x+ and set minimum memory to 5GB. if you are using WSL2, you will need to create a file call .wslconfig and set the minimum memory there.
# turn off all wsl instances such as docker-desktop
wsl --shutdown
notepad "$env:USERPROFILE/.wslconfig"Edit the file to this
[wsl2]
memory=8GB # Limits VM memory in WSL 2 up to 8GB
processors=4 # Makes the WSL 2 VM use two virtual processors- Create a new folder named airflow.
- Set Airflow user
On Linux, the quick-start needs to know your host user-id and needs to have group id set to 0. Otherwise the files created in dags, logs and plugins will be created with root user. You have to make sure to configure them for the docker-compose:
mkdir -p ./dags ./logs ./pluginsecho -e "AIRFLOW_UID=$(id -u)" > .env 3. import official docker-compose
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/stable/docker-compose.yaml'I found the file to be overwhelming but once you have it running, you will understand the different services.
4. Create Dockerfile
If you want to add python packages, you need to have a docker file with an airflow image. You will need to change the docker-compose so that it builds from the dockerfile. Replace the image tag with the lines below.
build:
context: .
dockerfile: ./DockerfileIn x-airflow-common-env, the following will be added:
GOOGLE_APPLICATION_CREDENTIALS: /.google/credentials/google_credentials.json
AIRFLOW_CONN_GOOGLE_CLOUD_DEFAULT: 'google-cloud-platform://?extra__google_cloud_platform__key_path=/.google/credentials/google_credentials.json'
GCP_PROJECT_ID: 'xxxxx'
GCP_GCS_BUCKET: 'xxxxxx'Problems
I spent a half a day figuring out a permission error when building. One thing is that it was very vague and could not pinpoint where the issue was. Solved it by using sudo. Figured out it is the UID needs to be 0.
DAG File
The location of the files are under volumes in the docker-compose file.
- ./dags_new:/opt/airflow/dags
The file consists of tasks which can be different operators. Operators are predefined tasks such as python functions, bash commands etc. IT could also have sensors, subclass of operators that which wait for external event to happen. After all that is done, you need to declare the flow of the tasks. This done using >> and << .
first_task >> second_task >> third_task
This shows that first task depends on second task and the second task depends of the third task. Each DAG must have a scheduled interval. Interval is can be written using the cronjob syntax.
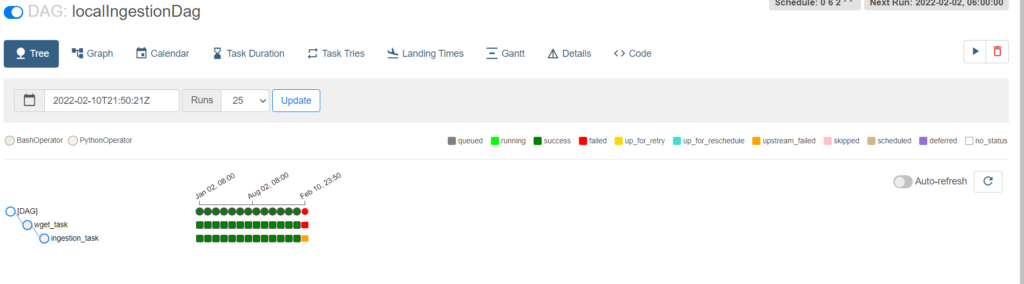
DAG can be scheduled to simulate past years jobs.
Problems
I had connection issues when uploading the file to GCP. The problem was that my internet was too slow.
SUMMARY
This week was familiarizing ourselves with airflow. Designing the workflow is dependent on the use case. What to lookout for is the flow and make sure that retries do not affect the flow. The documentation is very detailed and can help in designing the flow once you understand the use case. Also spent most of the time troubleshooting the code.
Reference