I had to skip week 6 about Kafka since it needed a lot of time and because I was not going to use it in the project. For this project, I will be analyzing Iowa liquor sales which are updated every month. The source of the data is found here and the data is consumed via API.
I created two branches on Github, one for dev and the other for production. The source for the project can be found here.
I used the steps below to complete the project:
- Create VM and BigQuery table and dataset in GCP using terraform
- Create a docker image of airflow and dbt
- Create extract and load dags
- Create dags to execute dbt for data transformation
- Deploy to VM
- Create Reports using Data Studio
Create VM and BigQuery table and dataset in GCP using terraform
- Create a project in GCP
2. Create service account
From here, create the project service account. We will need the following permissions (for production case, limit the permissions to the minimum):
- compute admin
- Bigquery admin
3. Add key to the service account and download the json file
4. Create a folder called terraform and inside create a file called main.tf. Then add the initial provider details. run terraform init
provider "google" {
project = var.project
region = var.region
credentials = var.gcp-creds
}
5. Add the compute instance , firewall configuration and bigquery details
resource "google_compute_instance" "default" {
name = "iowa-vm"
machine_type = "custom-2-8192" #ec2 machine with 2vcpu and 8gb ram
zone = "us-central1-a"
boot_disk {
initialize_params {
image = "ubuntu-os-cloud/ubuntu-1804-lts"
size = 100 // size of the disc
}
}
network_interface {
network = "default"
access_config {
// VM will be give exteranl IP address
}
}
metadata_startup_script = "sudo apt-get update && sudo apt-get install docker wget -y" # making sure that docker is installed
tags = [ "http-server","https-server" ]
}
resource "google_compute_firewall" "http-server" { # allowing port 8080 and 80 to be accessed
name = "allow-default-http"
network = "default"
allow {
protocol = "tcp"
ports = [ "80","8080","8000" ]
}
source_ranges = ["0.0.0.0/0"]
target_tags = [ "http-server" ]
}
output "ip" {
value = "${google_compute_instance.default.network_interface.0.access_config.0.nat_ip}"
}
resource "google_bigquery_dataset" "dataset" {
dataset_id = var.BQ_DATASET
project = var.project
location = var.region
}
6. Create a variables.tf file that will contain all the variables
variable "project" {
description = "GDP PROJECT ID"
}
variable "region" {
description= "Resource for GDP closest to location"
default = "us-central1"
type = string
}
variable "gcp-creds" {
description = "GDP SERVICE ACCOUNT KEY"
sensitive = true
}
variable "BQ_DATASET" {
description = "BigQuery Dataset that raw data (from GCS) will be written to"
type = string
default = "iowa_data"
}
variable "BQ_TABLE" {
description="Raw data table"
default = "sales_raw_data"
}
7. run terraform init -upgrade then terraform apply .For the key json file that you downloaded, remove all next line and have one long text. This is what you will use when asked about gcp-creds.
8. Go to GCP console and make sure the VM is created well
7. ssh to the vm using
gcloud compute ssh --project=PROJECT_ID \
--zone=ZONE \
VM_NAME
Create a docker image of airflow
- Create a folder called docker
- Inside the docker folder, create docker-compose.yml and Dockerfile
We will have two postgres instances: one for airflow and another for dbt.
version: '3'
services:
postgres-airflow:
image: postgres
environment:
POSTGRES_PASSWORD: pssd
POSTGRES_USER: airflowuser
POSTGRES_DB: airflowdb
AIRFLOW_SCHEMA: airflow
expose:
- 5432
restart: always
volumes:
- ./script_postgress:/docker-entrypoint-initdb.d
postgres-dbt:
image: postgres
environment:
POSTGRES_PASSWORD: pssd
POSTGRES_USER: dbtuser
POSTGRES_DB: dbtdb
DBT_RAW_DATA_SCHEMA: dbt_raw_data
DBT_SCHEMA: dbt
expose:
- 5432
restart: always
volumes:
- ./data:/opt/iowa/data
The add the airflow service which will be built using the dockerfile. The image will be python, airflow and dbt will be installed using pip.
airflow:
build: .
restart: always
environment:
DBT_PROFILES_DIR: /opt/iowa/dbt
AIRFLOW_HOME: /opt/iowa/airflow
AIRFLOW__CORE__DAGS_FOLDER: /opt/iowa/airflow/dags
AIRFLOW__CORE__EXECUTOR: LocalExecutor
AIRFLOW__CORE__PARALLELISM: 4
AIRFLOW__CORE__DAG_CONCURRENCY: 4
AIRFLOW__CORE__MAX_ACTIVE_RUNS_PER_DAG: 4
AIRFLOW__CORE__LOAD_EXAMPLES: 'false'
# AIRFLOW__ADMIN__HIDE_SENSITIVE_VARIABLE_FIELDS: False
# Postgres details need to match with the values defined in the postgres-airflow service
POSTGRES_USER: airflowuser
POSTGRES_PASSWORD: pssd
POSTGRES_HOST: postgres-airflow
POSTGRES_PORT: 5432
POSTGRES_DB: airflowdb
# postgres-dbt connection details. Required for the inital loading of seed data
# Credentials need to match with service postgres-dbt
DBT_POSTGRES_PASSWORD: pssd
DBT_POSTGRES_USER : dbtuser
DBT_POSTGRES_DB : dbtdb
DBT_DBT_SCHEMA: dbt
DBT_DBT_RAW_DATA_SCHEMA: dbt_raw_data
DBT_POSTGRES_HOST: postgres-dbt
GOOGLE_APPLICATION_CREDENTIALS: /.google/credentials/google_credentials_iowa.json
AIRFLOW_CONN_GOOGLE_CLOUD_DEFAULT: 'google-cloud-platform://?extra__google_cloud_platform__key_path=/.google/credentials/google_credentials_iowa.json'
GCP_PROJECT_ID: 'iowa-project-de'
GCP_GCS_BUCKET: 'iowa_data_lake'
GCP_BQ_DATASET: 'iowa_data'
DEPLOY_STATUS: 'dev'
depends_on:
- postgres-airflow
- postgres-dbt
ports:
- 8000:8080
volumes:
- ./dbt:/opt/iowa/dbt
- ./data:/opt/iowa/data
- ./airflow:/opt/iowa/airflow
- ~/.google/credentials/:/.google/credentials:ro
The dockerfile will have the code below. All the packages to be installed will be put in the requirements text file.
FROM python:3.9
COPY requirements.txt .
RUN pip install -r requirements.txt
RUN pip uninstall markupsafe -y
RUN pip install markupsafe==2.0.1
RUN mkdir /project
COPY scripts/ /project/scripts/
COPY dbt/profiles.yml /root/.dbt/profiles.yml
RUN chmod +x /project/scripts/airflow_init.sh
ENTRYPOINT [ "/project/scripts/airflow_init.sh" ]
Add airflow initialization script airflow_init.sh that is used to create the user.
#!/usr/bin/env bash
# Setup DB Connection String
AIRFLOW__CORE__SQL_ALCHEMY_CONN="postgresql+psycopg2://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${POSTGRES_HOST}:${POSTGRES_PORT}/${POSTGRES_DB}"
export AIRFLOW__CORE__SQL_ALCHEMY_CONN
AIRFLOW__WEBSERVER__SECRET_KEY="openssl rand -hex 30"
export AIRFLOW__WEBSERVER__SECRET_KEY
DBT_POSTGRESQL_CONN="postgresql+psycopg2://${DBT_POSTGRES_USER}:${DBT_POSTGRES_PASSWORD}@${DBT_POSTGRES_HOST}:${POSTGRES_PORT}/${DBT_POSTGRES_DB}"
cd /opt/iowa/dbt/iowa && dbt compile
rm -f /opt/iowa/airflow/airflow-webserver.pid
sleep 10
airflow db upgrade
sleep 10
airflow connections add 'dbt_postgres_instance_raw_data' --conn-uri "${DBT_POSTGRESQL_CONN}"
airflow users create \
--username airflow \
--firstname fname \
--lastname lname \
--password airflow \
--role Admin \
--email [email protected]
airflow scheduler & airflow webserver
Have a file to initialize the postgres database: init-user-db.sh. This will be put in a folder called script-postgres.
#!/bin/bash
set -e
psql -v ON_ERROR_STOP=1 — username "$POSTGRES_USER" — dbname "$POSTGRES_DB" <<-EOSQL
ALTER ROLE $POSTGRES_USER SET search_path TO $AIRFLOW_SCHEMA;
— CREATE SCHEMA IF NOT EXISTS $DBT_SCHEMA AUTHORIZATION $POSTGRES_USER;
— CREATE SCHEMA IF NOT EXISTS $DBT_SEED_SCHEMA AUTHORIZATION $POSTGRES_USER;
CREATE SCHEMA IF NOT EXISTS $AIRFLOW_SCHEMA AUTHORIZATION $POSTGRES_USER;
SET datestyle = "ISO, DMY";
EOSQL
You will need to initialize dbt on local machine so that it creates the folders. You will need to create the projects.yml file the run dbt init .
iowa:
outputs:
dev:
dataset: iowa_staging
fixed_retries: 1
keyfile: /.google/credentials/google_credentials_iowa.json
location: us-central1
method: service-account
priority: interactive
project: iowa-project-de
threads: 4
timeout_seconds: 300
type: bigquery
prod:
dataset: iowa_prod
fixed_retries: 1
keyfile: /.google/credentials/google_credentials_iowa.json
location: us-central1
method: service-account
priority: interactive
project: iowa-project-de
threads: 4
timeout_seconds: 300
type: bigquery
target: dev
With that done, docker is ready to be built.
- docker compose build
- docker-compose up -d
Create extract and load dags
For the extract and load dags, Make sure that when each task is run multiple times, the results will be the same: idempotent.
With that in mind, create 3 tasks in EL_dag. One to get data from the API and convert the json data to parquet file, then to load the data to my bucket and finally to remove the local file system. Data is uploaded every 2nd day of the month. Therefore scheduled that the data is extracted every 3rd day at 1am. You have to add the catch up option so that the data start from 2012 to this month.
Add a dag that will create the external table — BQ_dag. This will done only once since you have put all the files under on major folder ad referenced it while creating the table: “sourceUris”:[f”gs://{BUCKET}/raw/iowa_sales/*”]. This means that all files under that folder will be used in creating the table. Do this to avoid calling the task every time a file is loaded.
Create dags to execute dbt for data transformation
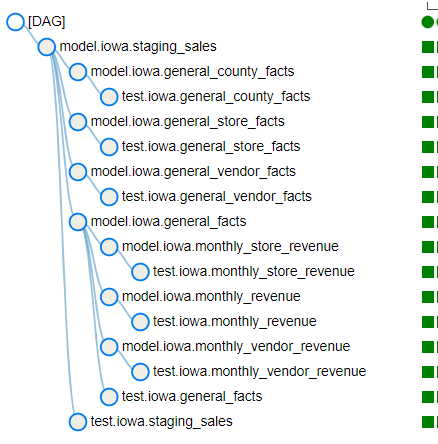
Create a staging view : staging_sales.sql that will transform the date field to datetime and all fields that are related to money to numeric. Also turn all the names to lowercase. Partition the view by months since the reports generated will be by month.
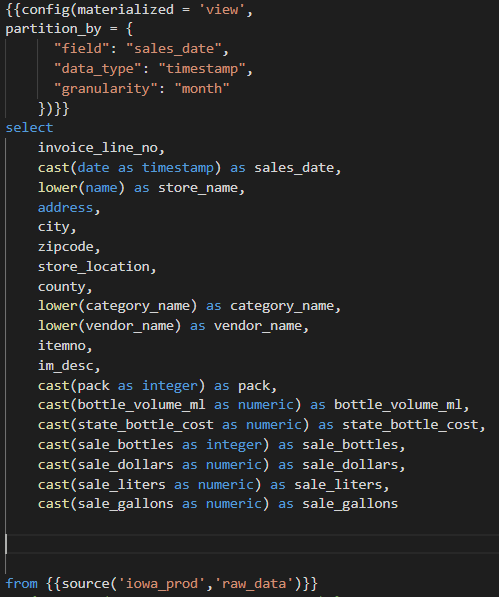
From the staging view, Create a sales mart that will have incremental tables which will contain vendors, stores and general report. All the tables will be partitioned by sales_date. For vendors and stores, clustere based on vendors and sales respectively.
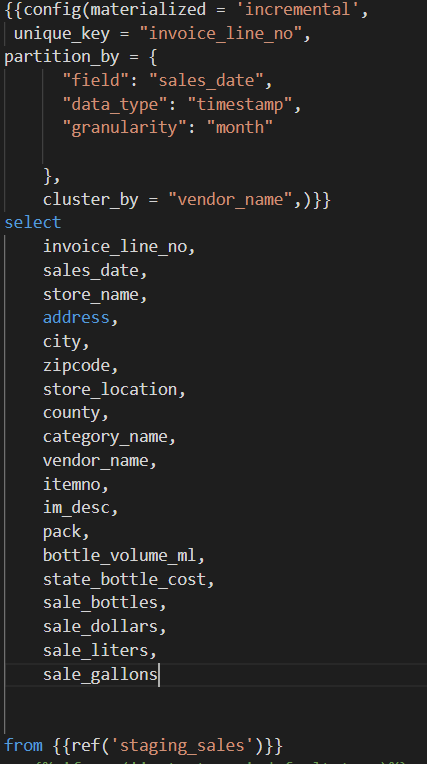
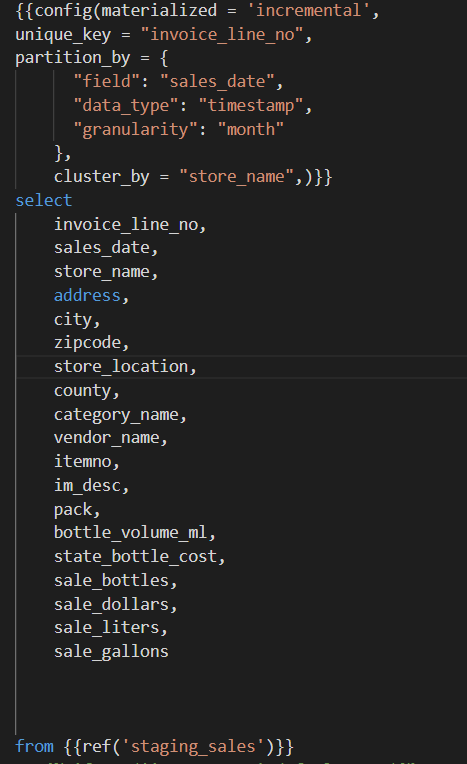
Then create monthly reports for each store and each vendor. These reports can be used in the planning of inventory.
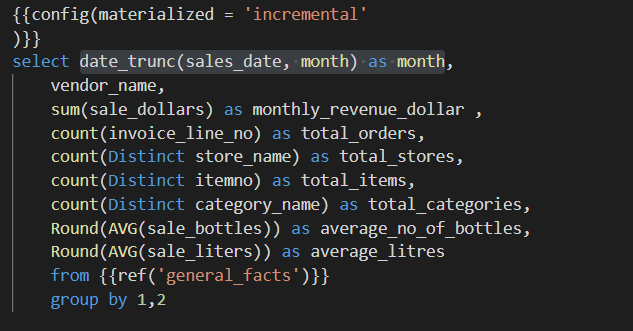

These models need to be run every month so as to add the new data into the tables. The models will be run individually.
This is where airflow comes in. The following steps will be followed:
- dbt compile will create a manifest.json that is stored in the target folder. This file contains all the models and there dependencies. This command will be run every time there is a new model created or any changes to the models regarding dependencies
- Loop through the json file and get all the models. This will create the model run as tasks.
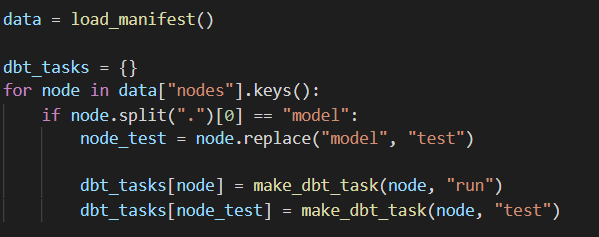


- Run the models. They will be run the same time as the extract and load dags but at 4am. This will give time for the data to be loaded to the bucket.
Deploy to VM
Wanted to create a CI/CD pipeline using Google compose and Google build, however they do not support docker-compose. Normal deployment made sense here.
Save all the work done and push the code to GitHub. Make sure to ignore all the files under .terraform and also the credentials json file
On the created VM, I installed docker compose:
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-composedocker-compose --versionClone the code from the git on the VM
Move inside docker folder and run
sudo docker-compose up -d
Go to http://<publicip>:8000
Airflow should be running there.
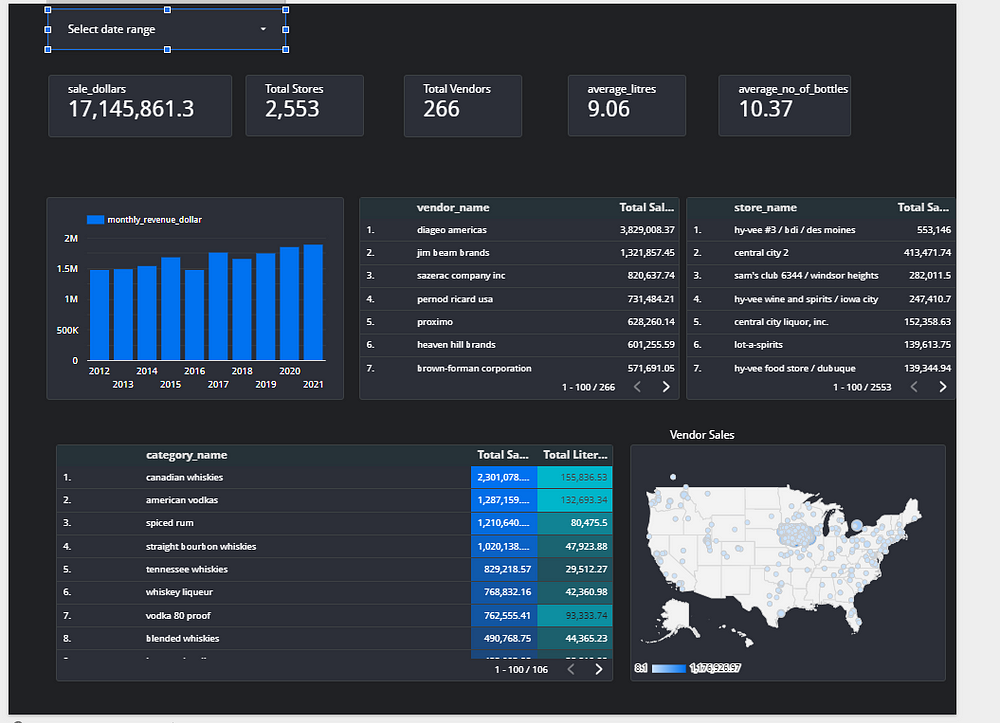
Create Reports using Data Studio
Add all the tables created for the sales mart and create charts. I created one page that had the summary of the sales done. This is just a simple visualization and there is much information than can be extracted from the data. The report can be found here