
This week’s lesson was weird since I, like other people who have not yet had data greater than a TB to work with, don’t understand why we need spark. I have heard about it and the way it is being described is a cool tool to have but everything we learnt can be done with the other tools we learnt in the previous week. So I will try to summarize what I have learnt so far.
Data Processing
Before we look at spark, we need to understand what it is used for. In data processing, there are two types of data flow:
- Batch Processing — This is where data is processed after an interval of time or occurrences depending on businesses. An example would be settlements: in some cases they are done end of day. The transaction data would be sent to a data warehouse and the business team will take care of that depending on the organization structure.
- Streaming — This is when data is processed in real-time. An example would recommendation system or marketing for discounts or sales.
What is Spark?
Apache Spark is an open-source unified analytics engine for large-scale data processing as per the website.
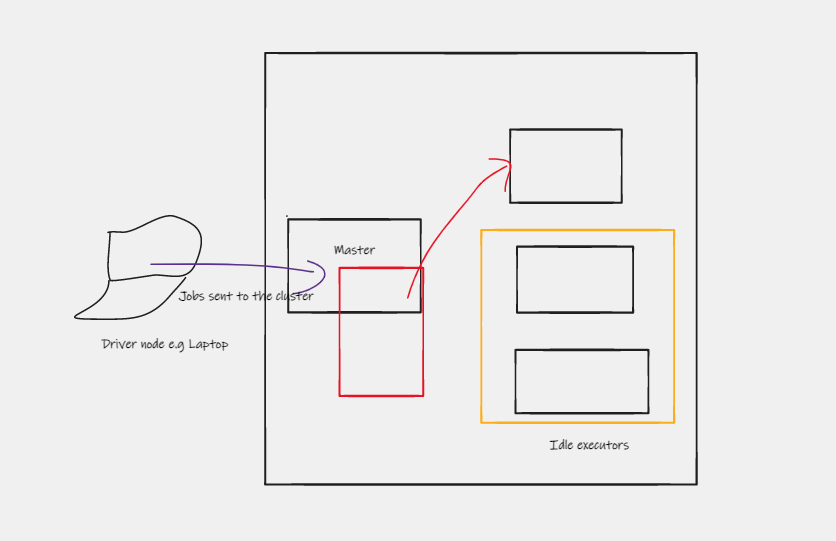
It uses a distributed processing system, where it has a master and executors as shown below. It is lightning fast when processing big data because it uses in-memory to store data. It is mostly used for processing data in a data lake without leaving the data lake. It is ideal for >1TB size of data and for batch processing. It is written in Scala and there are wrappers for other languages such as python (pyspark) , Java, R.
It pulls data from the data lake to its engine, processes it and returns the processed data to the data lake.
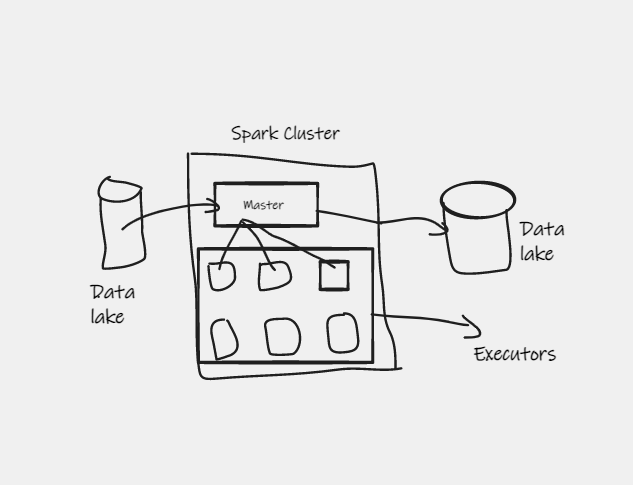
How is it different from Apache Hadoop? Hadoop is has storage. This means that the data is in Hadoop and the code is what is sent to the executors instead of the data. Spark and Hadoop can complement each other.
When to use spark
- Spark is used for processing big files in a data lake . Although one can use Hive/Presto/Athena to perform Sql in a data lake
- When SQL does not solve your problem. Sql has limitations and working with supported languages such as R, Java, Python and Scala will work
When not to use spark
- When you have small dataset
- Low computing capacity — Stores data in-memory unless there is no space. This is what makes it fast. There for you machines need high computing capacity. If it does not, it is better to use Apache Hadoop
- If you need real-time, low latency processing its better to work with Apache Kafka.
- When you have a multi-user setup with shared memory. If you increase users, it complicates memory allocation across the team. In such a use-case, Hive is better.
Setting up Spark on Docker (Linux/WSL2)
I did not want to work on my machine or the Virtual machine in the cloud. I thought working from docker will help me understand the architecture better. I underestimated the work need to set it up since I really touch our Infrastructure at work. Some of the challenges I encountered was combining Jupyter and the Webui. When one worked, the other did not.
After 20hrs of trying to write my own Dockerfile and Docker-compose, I found this amazing Github repo . He explains how Jupyter and the spark cluster will communicate.
- Clone the repo
git clone https://github.com/cluster-apps-on-docker/spark-standalone-cluster-on-docker - Create two folders called code and data. This will be the volumes that we will mount.
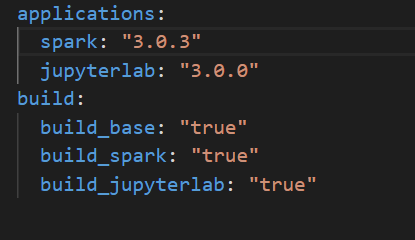
- You will need to change the spark version in 3.0.3. This will be done in
build/build.yml
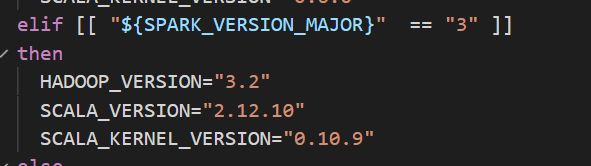
- Change hadoop version in build/build.sh
- Change the docker-compose.yml file to add the volumes and also rename spark image since you changed in
version: "3.6"
volumes:
shared-workspace:
name: "build"
driver: local
services:
jupyterlab:
image: jupyterlab:3.0.0-spark-3.0.3
container_name: jupyterlab
ports:
- 8888:8888
- 4040:4040
volumes:
- ../code:/opt/workspace/code
- ../data:/opt/workspace/data
spark-master:
image: spark-master:3.0.3
container_name: spark-master
ports:
- 8080:8080
- 7077:7077
volumes:
- ../code:/opt/workspace/code
- ../data:/opt/workspace/data
spark-worker-1:
image: spark-worker:3.0.3
container_name: spark-worker-1
environment:
- SPARK_WORKER_CORES=1
- SPARK_WORKER_MEMORY=512m
ports:
- 8081:8081
volumes:
- ../code:/opt/workspace/code
- ../data:/opt/workspace/data
depends_on:
- spark-master
spark-worker-2:
image: spark-worker:3.0.3
container_name: spark-worker-2
environment:
- SPARK_WORKER_CORES=1
- SPARK_WORKER_MEMORY=512m
ports:
- 8082:8081
volumes:
- ../code:/opt/workspace/code
- ../data:/opt/workspace/data
depends_on:
- spark-master
- You will need to add wget as one of the packages being installed under Jupyterlab. Go to
build/docker/jupyterlab/Dockerfile

- Comment Scala and R kernels in Jupyterlab
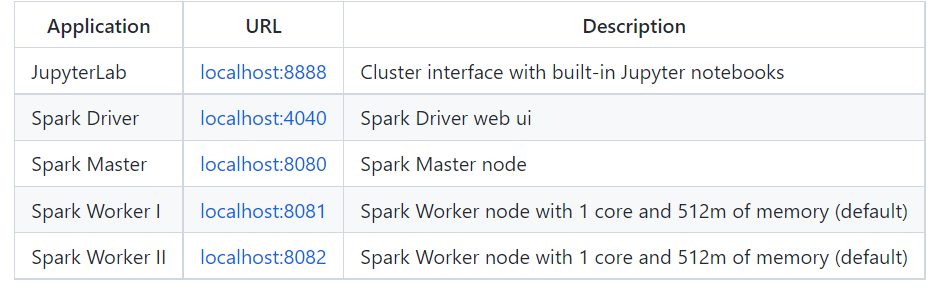
- Now you are ready to Start the cluster. It will build the first time.
docker-compose up -d
- Test whether pyspark is working in your notebooks. Create a notebook under code folder and paste this code:
# While inside code folder
!wget -P ../data https://nyc-tlc.s3.amazonaws.com/trip+data/fhvhv_tripdata_2021-02.csv
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("local[*]") \
.appName('test') \
.getOrCreate()
df = spark.read \
.option("header", "true") \
.csv('../data/fhvhv_tripdata_2021-02.csv')
df.show()
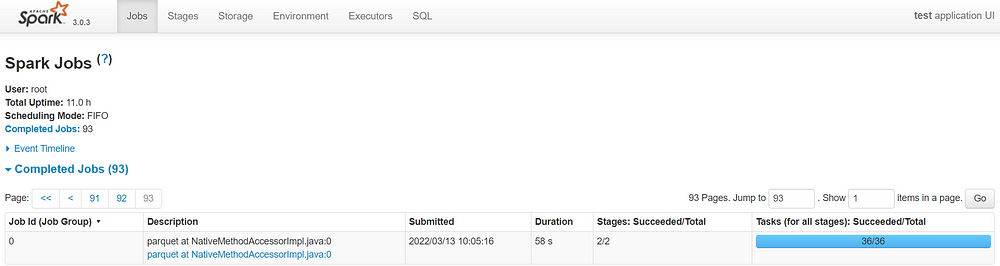
In the webUI localhost:4040 , you can look at the jobs.
Spark Dataframes
If you have worked with pandas, working with pyspark will be easy. You will need to adapt to the syntax. They are built on top of Resilient Distributed Datasets (RDD)
Unlike pandas dataframe, spark dataframe does not pick a file’s schema. It turns everything to String unless to tell it to infer the schema. It does not also pick the header unless told to. Example, from the above code:
df = spark.read \
.option("header", "true") \
.option("inferSchema", "true")\
.csv('../data/fhvhv_tripdata_2021-02.csv')
df.show()
You can also create you own schema.
from pyspark.sql import types
schema = types.StructType([
types.StructField('hvfhs_license_num', types.StringType(), True),
types.StructField('dispatching_base_num', types.StringType(), True),
types.StructField('pickup_datetime', types.TimestampType(), True),
types.StructField('dropoff_datetime', types.TimestampType(), True),
types.StructField('PULocationID', types.IntegerType(), True),
types.StructField('DOLocationID', types.IntegerType(), True),
types.StructField('SR_Flag', types.StringType(), True)
])
df = spark.read \
.option("header", "true") \
.schema(schema) \
.csv('../data/fhvhv_tripdata_2021-02.csv')
Given that Spark does distributed processing, you have to take advantage of the resources. If you have one file that is submitted to the engine, master node will allocate task to only one executor. The others will be idle.
In such a scenario, one needs to create partitions of the file so that each executor can a task its processing hence making the processing faster. To do so, one can use the repartitions to do that and write the file as parquet files. The file become smaller.
output_path = '../data/fhvhv/2021/02'
df.repartition(24)\
.write.parquet(output_path)
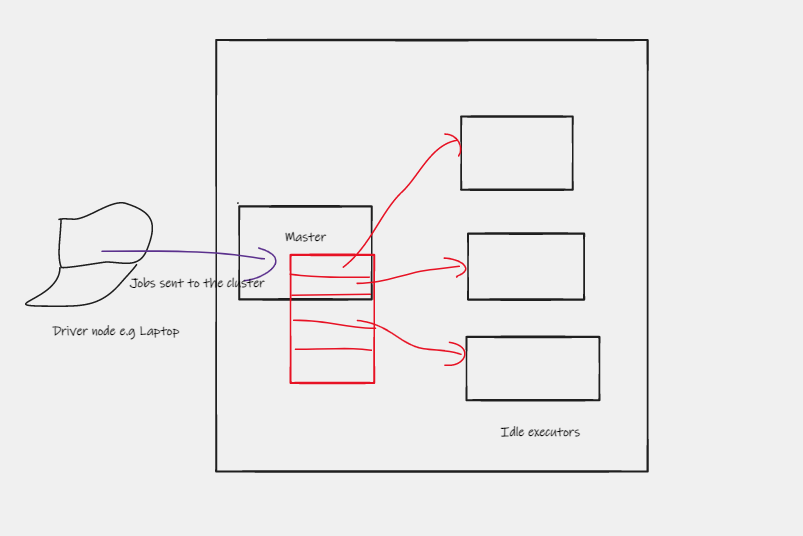
After the executor finishes a task, it alerts the master and it is given another file to process.
Actions Vs Transformers and User Defined Functions (UDF)
Transformations commands change the way the dataframe looks and are not executed immediately. They are also referred to as lazy commands. Spark creates job flow and will only execute them when an action is called. Example Select, Filter, join, group by
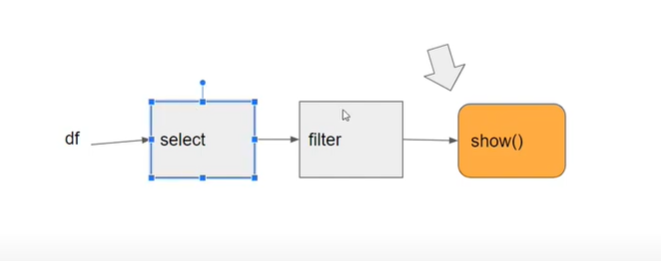
Action commands are executed immediately and are also referred to as eager commands. Example are show, take head, write
Spark has inbuilt functions that can be used in the processing of data. Some examples include transforming column to date.
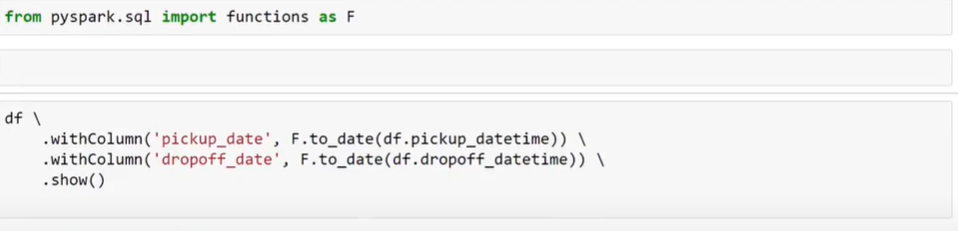
One can also create their own functions and apply them to the dataframe. Just like pandas 🙂 . This functions are called User Defined Functions (UDF).
- First create the function
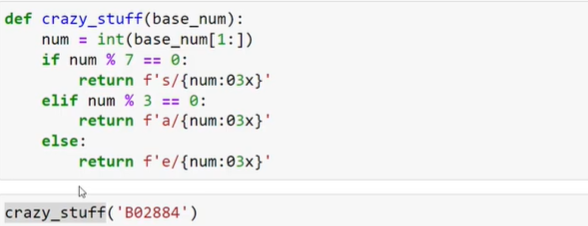
- Then declare the function as a UDF

- Now you can apply it like any other function

Working with SQL
In spark you can also use SQL. For simpler processing and if you know SQL, you can use spark SQL. The syntax is the the same as what we had in dbt.
- First you need to register the table
df_parquet = spark.read.parquet('../data/fhvhv/2021/02/*')
df_parquet.registerTempTable('fhvhv_tripdata')
- Then you can write your sql statement. This is a transformation hence will not be executed unless an action is called.
data_trips = spark.sql("""
SELECT COUNT(*) as trips from fhvhv_tripdata WHERE CAST (pickup_datetime AS DATE) = '2021-02-15'
""")
data_trips.show()
Note: If you add show at the end of the statement, the variable data_trips will be null.
data_trips = spark.sql("""
SELECT COUNT(*) as trips from fhvhv_tripdata WHERE CAST (pickup_datetime AS DATE) = '2021-02-15'
""").show()
#will return null
When working with group by, the distributed nature of spark makes it interesting when performing group by. Lets take an example of the code below:
df_yellow_revenue = spark.sql("""
SELECT
date_trunc('hour', tpep_pickup_datetime) AS hour,
PULocationID AS zone,
SUM(total_amount) AS amount,
COUNT(1) AS number_records
FROM
yellow
WHERE
tpep_pickup_datetime >= '2020-01-01 00:00:00'
GROUP BY
1, 2
""")
- The master will first allocate a partition file to each executor
- The executors will each the filter and group by and store the results in intermediate ‘files’
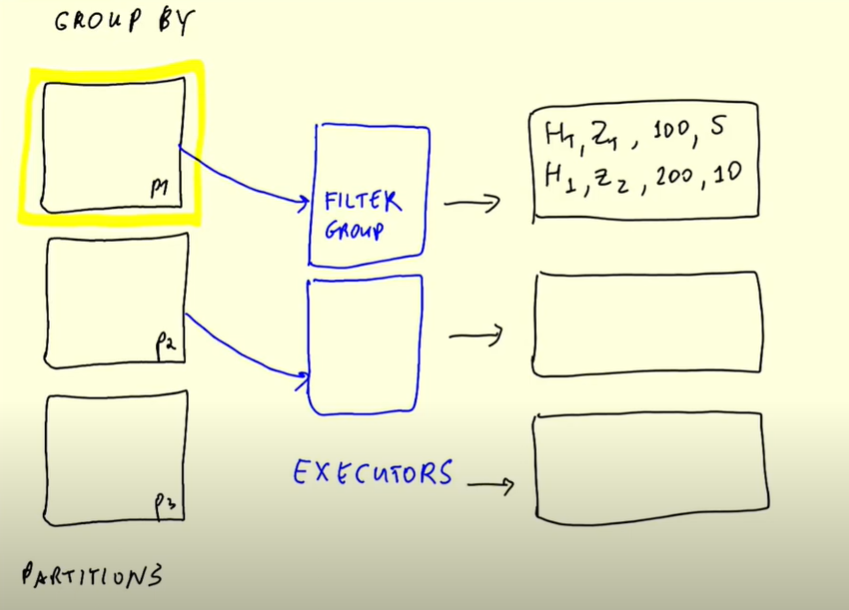
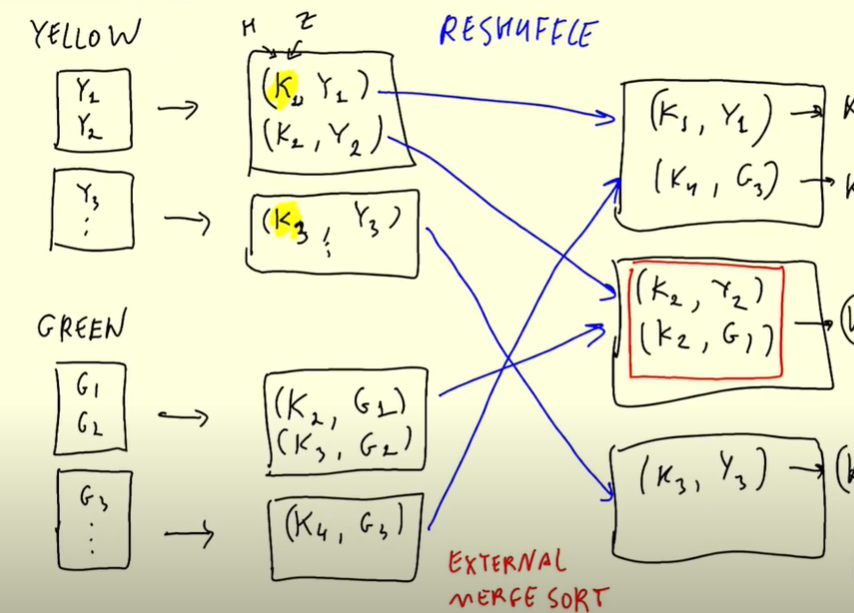
- The results in the intermediate results need to be combined. Therefore if some H1,Z1 data was in partition 3, they all need to be put together. This is called reshuffling. Data is moved across different partitions. Data with the same keys need to be in the same partition. In our data, the key is Hour and Zone. This is done by External merge sort algorithm.
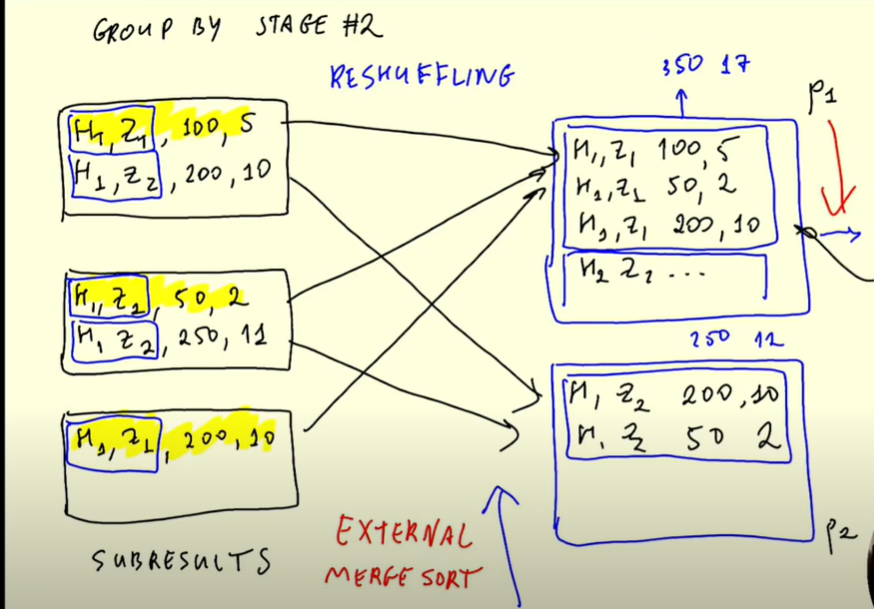
The same applies to joins and the difference will be stage one where instead of filtering and Grouping, it will be joining. Then the data will be reshuffled.
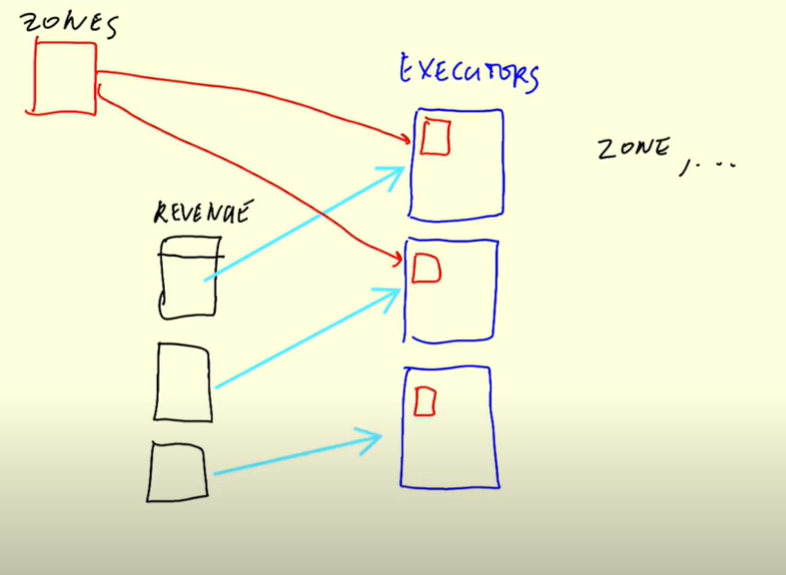
If you are joining a large table and a small one, you broadcast the values to all the executors hence no need of reshuffling.
This was just an introduction to Spark. There is more to be learnt and that can be done through projects. Adding it to my long TODO list
References
- Week 5 Lesson: https://github.com/DataTalksClub/data-engineering-zoomcamp/tree/main/week_5_batch_processing
- Spark on Docker: https://github.com/cluster-apps-on-docker/spark-standalone-cluster-on-docker
- https://towardsdatascience.com/the-what-why-and-when-of-apache-spark-6c27abc19527
- https://www.pluralsight.com/guides/when-to-use-apache-spark
- https://www.qubole.com/blog/apache-spark-use-cases/